This post is human-written and not AI generated or edited.
Hey all! We're introducing a new Neuronpedia core feature for exploring attention heads in collaboration with Anthropic, and we also provide a few updates to NLAs and SAEs, as well as a quick poll in the end.
HeadVis (Luger, Kamath, et al) is Anthropic's tool for exploring attention heads, and it's now available for 37 models on Neuronpedia, for a total of 36,000+ attention head dashboards.
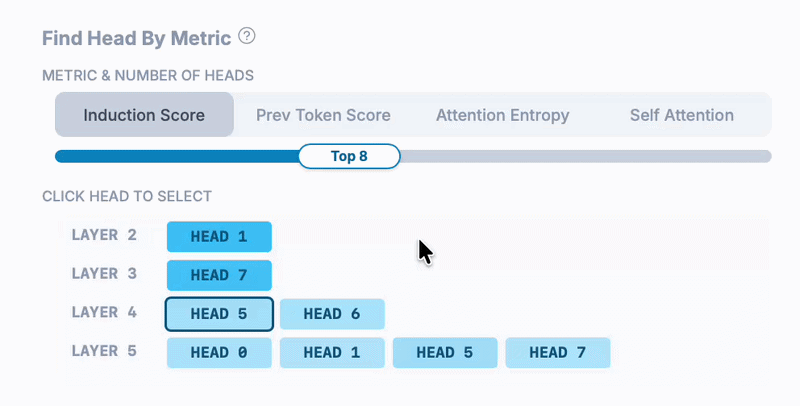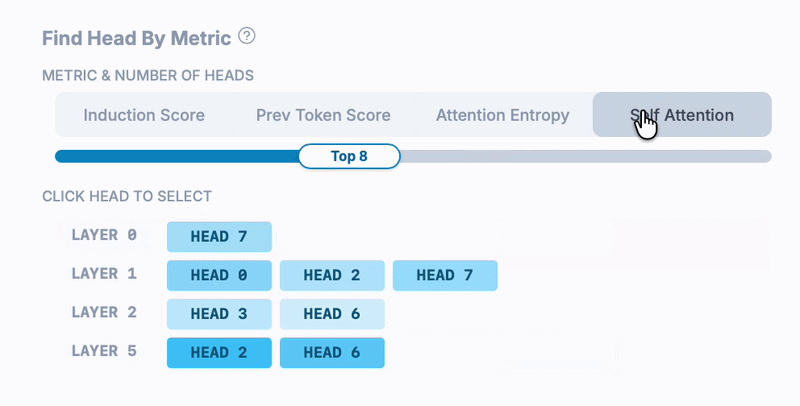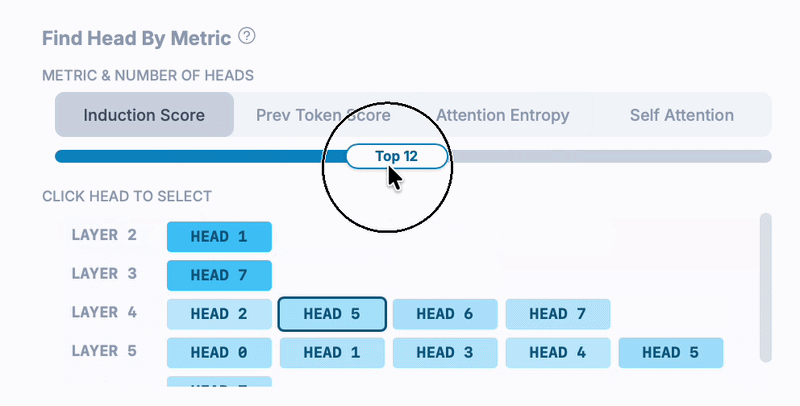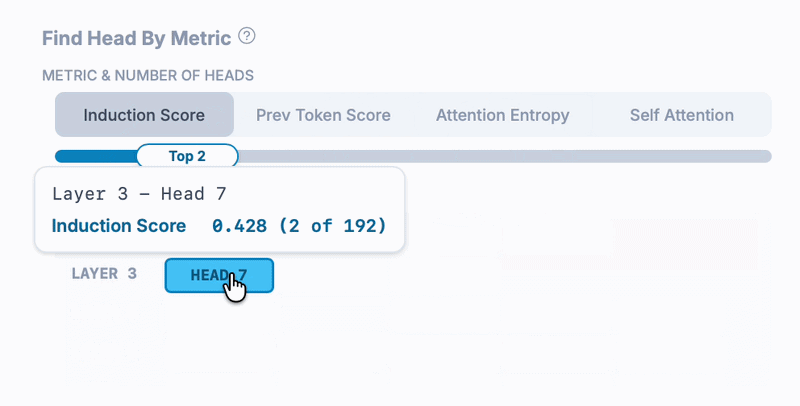
Let's examine an induction head (an attention head responsible for repeating previously seen token patterns like [A][B]...[A]->[B]) in Qwen3.6-27B:

In the sequence above, the term "Hypoxic vasoconstriction" is repeated multiple times. As we hover over the tokens in its name, the orange lines show the attention head looking back at previous copies of the species name (specifically, the token immediately after the previous instance of the current token) so it knows what to output next. The grey lines show the opposite: where the hovered token is being referenced by a future token.
The rest of the attention dashboard shows other metrics and visualizations such as self attention score, max attenetion distribution, and top query and key tokens.
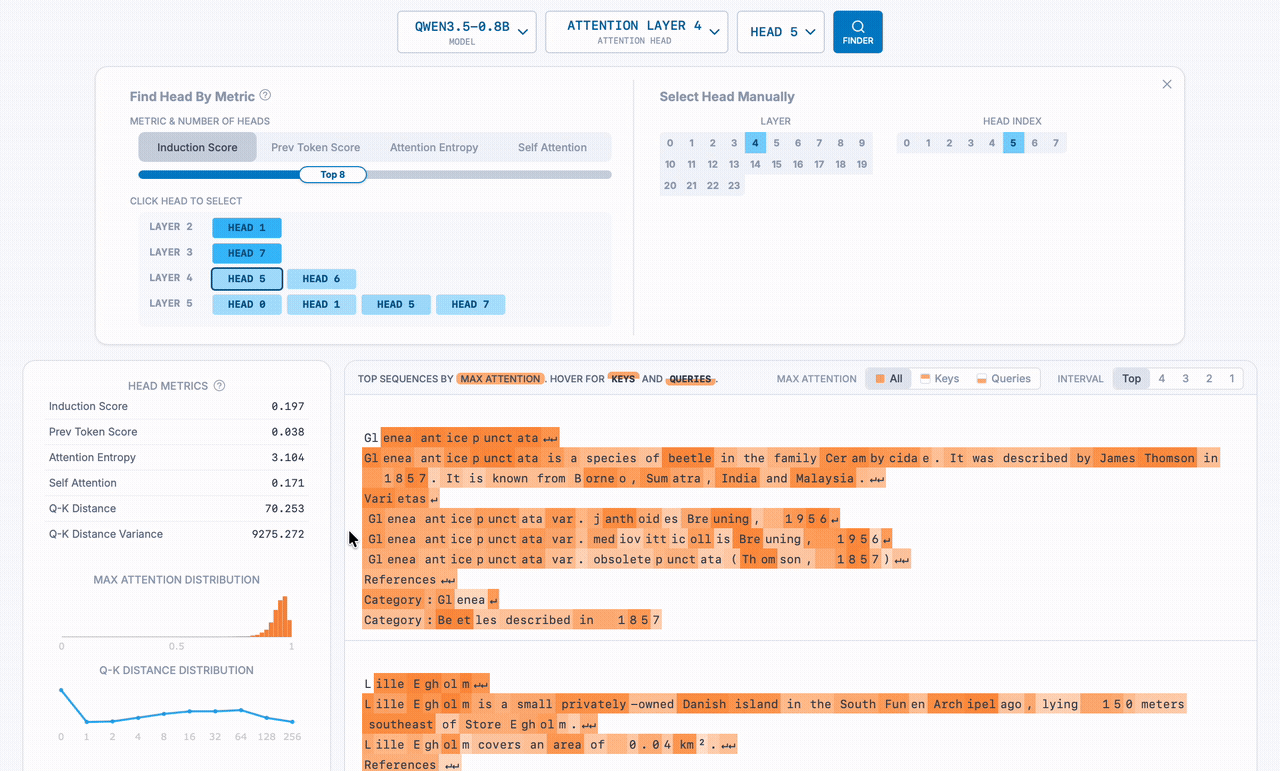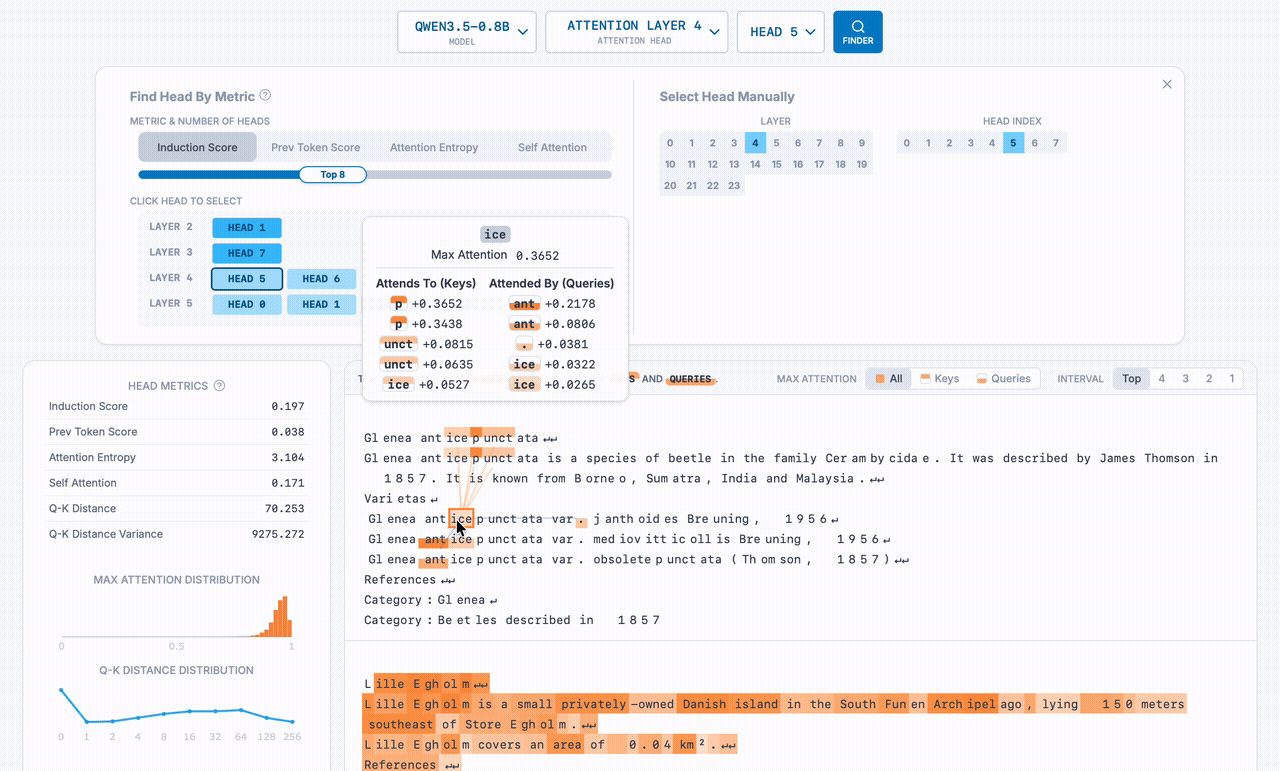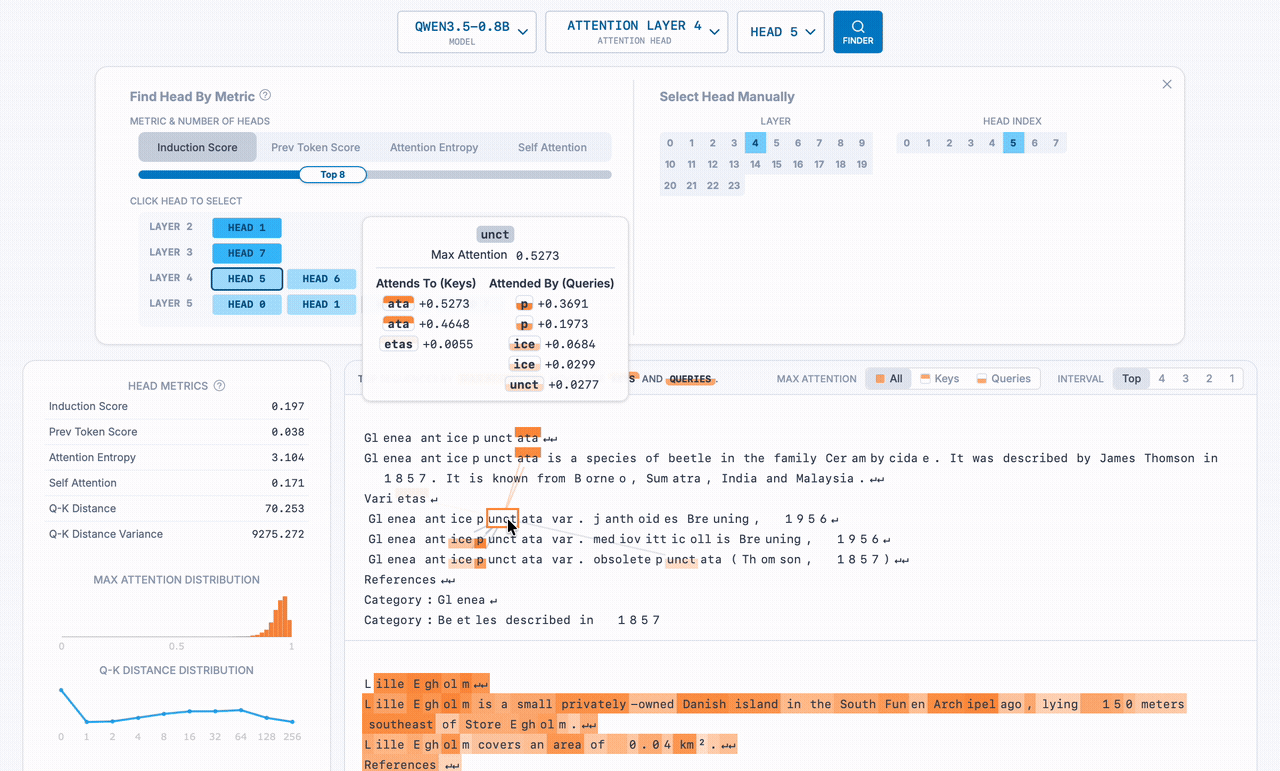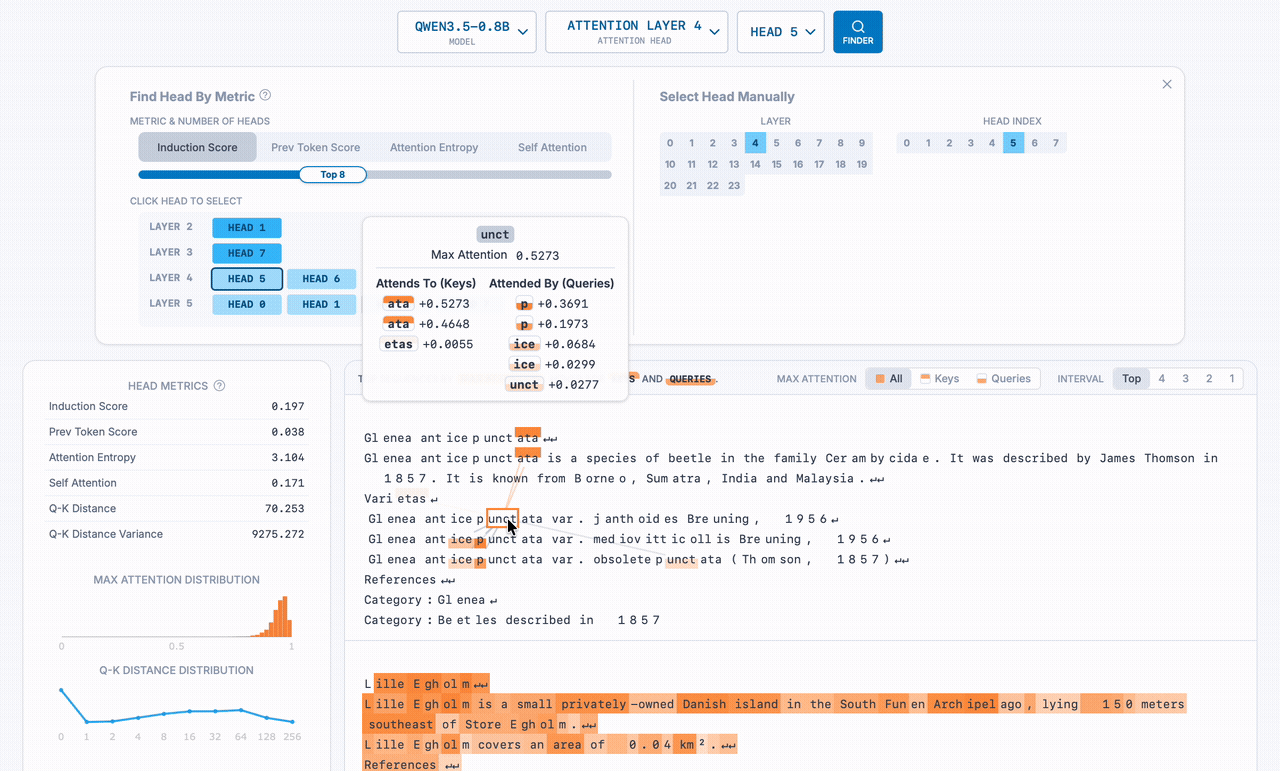
This Qwen 3.5 model has 24 layers and 8 heads per layer, for a total of 192 attention heads, so how did we find an induction head? The Head Finder (enabled by clicking "Finder" on an attention head dashboard) lets us find top N heads by notable, precomputed metrics. In this case, we filtered by top induction scores of all heads - calculated by averaging the induction-pattern attention values across many sequences.
Here's the Head Finder in action:
Since HeadVis is a core Neuronpedia integration, there are a few ways to access and share attention head dashboards:
Read Post (LessWrong) | Notebook
Contributor Francesco Zaffino previously demoed (notebook) using Gemma's NLA to explain SAE features. His new post extends this experiment in two ways:
Check out the post and the associated notebook.
Contributor Caleb DeLeeuw is working on NLAs for Gemma 4 E2B, and has trained a few versions of it. Surprisingly, the NLAs were trained on a 4GB consumer GPU! These NLAs are still a work in progress, but there are two versions for experimentation:
Example code for running these NLAs is available here.
Combined with the new SAEs from the last newsletter, here are the 14 new SAEs available on Neuronpedia, all with auto-interp explanations and available via our exports.
Our thanks to Modal for generously providing the compute used to train the Qwen 3.5 0.8B and 4B SAEs.
| Model | Layer | Link |
|---|---|---|
| Gemma 4 31B | 30 | 30-res-matryoshka-131k |
| Gemma 4 E2B | 17 | 17-matryoshka-res-65k |
| Gemma 4 E4B | 21 | 21-matryoshka-res-65k |
| Olmo 3 7B | 16 | 16-res-matryoshka-65k |
| Olmo 3 32B | 32 | 32-res-batchtopk-131k |
| Qwen 3 1.7B | 14 | 14-resid-batchtopk-65k__l0-80 |
| Qwen 3 8B | 18 | 18-resid-batchtopk-65k__l0-80 |
| Qwen 3 14B | 20 | 20-resid-batchtopk-65k__l0-80 |
| Qwen 3 32B | 32 | 32-resid-batchtopk-65k |
| Qwen 3.5 0.8B | 11 | 11-res-matryoshka-65k |
| Qwen 3.5 2B Base | 11 | 11-qwenscope-res-32k |
| Qwen 3.5 4B | 15 | 15-res-matryoshka-65k |
| Qwen 3.5 9B Base | 15 | 15-qwenscope-res-64k |
| Qwen 3.5 27B | 31 | 31-qwenscope-res-80k |
Neuronpedia currently runs >20 models for live inference, steering, graph generation, circuit tracing, and now NLAs in the API and on our interface. Which of the models do you care about the most, and which models should we add? Please take a minute toe answer the one question poll so that we can prioritize the models that you care about the most.
As always, please contact us with your questions, feedback, and suggestions.