
This post is human-written and not AI generated or edited.
If we could reliably read an AI model's thoughts, we'd be able to build safer AI systems. However, when we look inside a running model, we see huge arrays of numbers ("activations") that are difficult to understand.
Natural Language Autoencoders (NLAs) are models that directly translate these activations into natural language, so that we can read a model's internal thoughts in plain English.
NLAs build on top of previous work by Pan et al, Karvonen et al, Huang et al and others, with a key difference that NLAs are a pair of models trained in a mostly unsupervised manner: an Activation Verbalizer (AV) that translates activations into text, and an Activation Reconstructor (AR) that translates the text back into activations (for "scoring").
In this newsletter, we cover the NLA release, new features since the NLA release, and 🙋 opportunities to contribute: ways that you can add value to interpretability research that don't necessarily require a ton of experience. Opportunities to contribute are not an invitation to copy paste the thing into Claude/Codex and then copy paste the results back to us. Please use the AI as a copilot, not the director.
We're now explicitly labeling our posts as human-written. They've been and always will be human-written. We're not anti-using-AI (we use it all the time for coding and tasks), but at least in the current stage of AI development, we're think it's significantly better to be explicit.
Also, until now, we've used NotebookLM to generate an AI podcast summary for each post. It was an interesting experiment (and honestly, half of it was an excuse to use 'The Babble' pun as it relates to the Residual Stream). We'll no longer be doing this: even though The Babble is a summary tool, its net value wasn't high enough vs time invested and confusion about what it was. Goodbye to the Babble for now - but don't worry, Rizz the Frog is still here with us in the Residual Stream. 🌈🏞️
Okay, now back to NLAs!
NLAs are not perfect - they're relatively new, and a significant shortcoming is that NLAs can confabulate, or produce unexpected outputs or incorrect explanations. Read the paper's limitations section for details.
🙋 Opportunity to Contribute: Reliable NLA evals/benchmarks that aren't easily gameable.
Thanks to a feature request from Joseph Bloom, in your NLA chat, you can now edit the assistant message in addition to the user message:
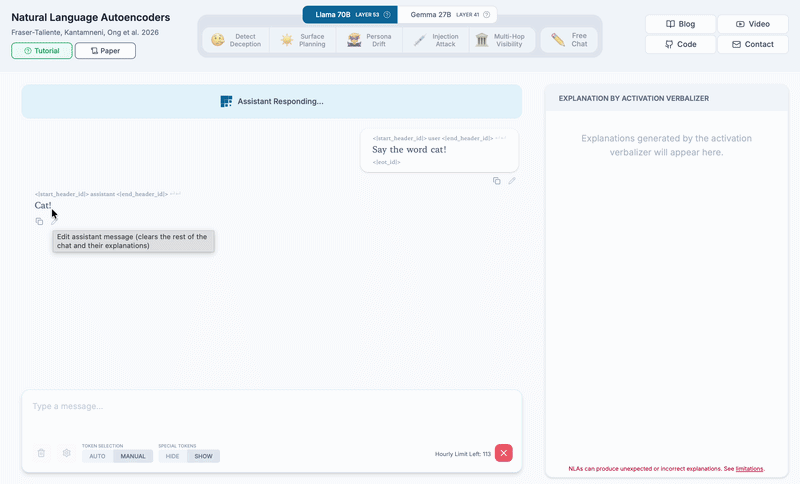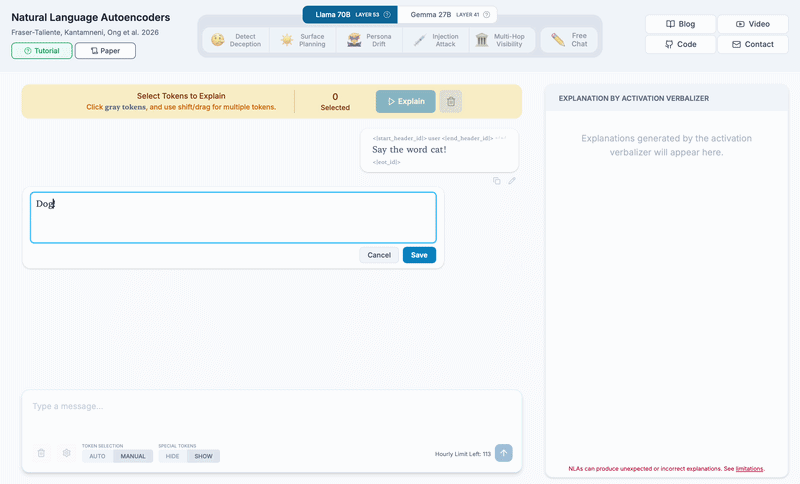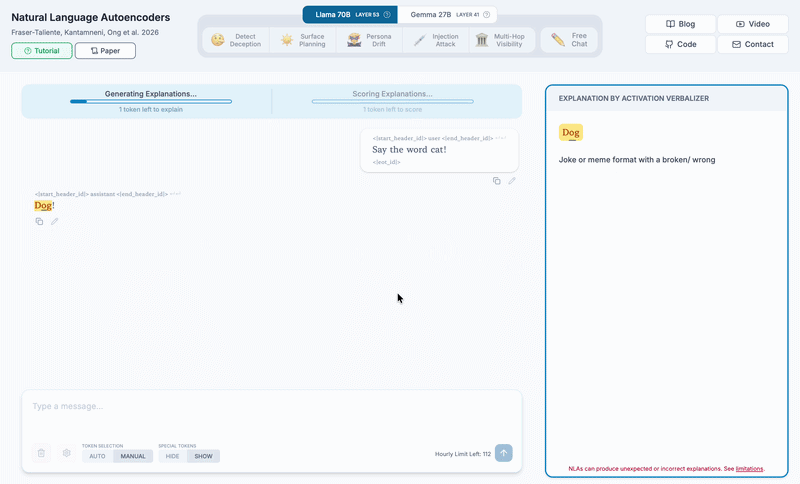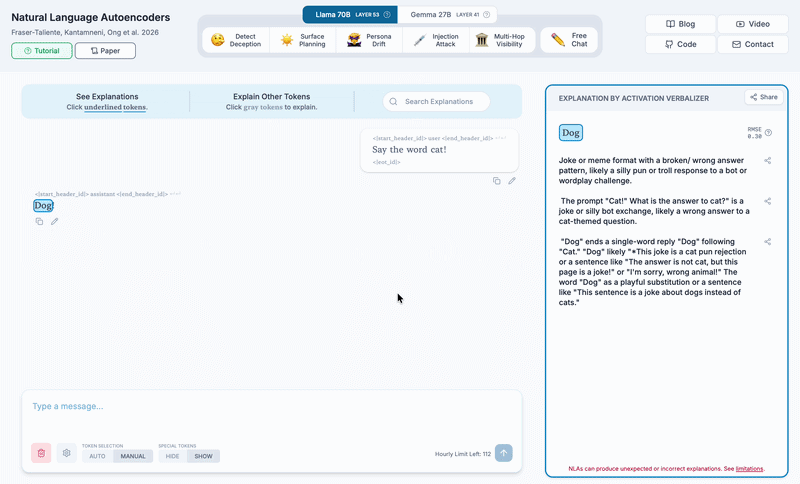
We edit the assistant response from cat to dog, then explain the dog token.
Neuronpedia exposes an NLA API for researchers to run experiments. The API currently supports the same two NLAs as the frontend, both running NLAs trained by Anthropic: gemma-3-27b-it with NLA source kitft-l41 and llama3.3-70b-it with NLA source kitft-l53. To ensure everyone has access, the default limit is a 120 explanation requests per hour per user (each explanation request can be for up to 16 tokens). If you need a higher limit for your research, please email us.
Anthropic provides an open source library for training and loading NLAs.
🙋 Opportunity to Contribute: New NLAs - Neuronpedia is accepting NLAs from contributors/researchers (similar to what we do for circuit tracer and SAEs). This gives us greater breadth of model coverage, and allows other researchers to compare NLAs from different models and layers. If you train an NLA that you'd like to share on Neuronpedia, let us know!
🙋 Opportunity to Contribute: NLA improvements/tweaks - update the way that NLAs are trained (eg warm-start prompts, hyperparameters, etc), or even a larger change that qualifies as a new NLA variant. Please submit these contributions as PRs to the public GitHub.
While experimenting with NLAs, we decided to throw SAE features/vectors into them to see what would happen. Surprisingly, they generated passable explanations for some SAE features. This was super unscientific, but then again, so was the way in which penicillin was discovered, so why not. 🤷 This section should be taken with a massive block of salt, as we (Decode) have no idea why this (sometimes) works. Special thanks to David Chanin for training SAEs to experiment with earlier NLA models.
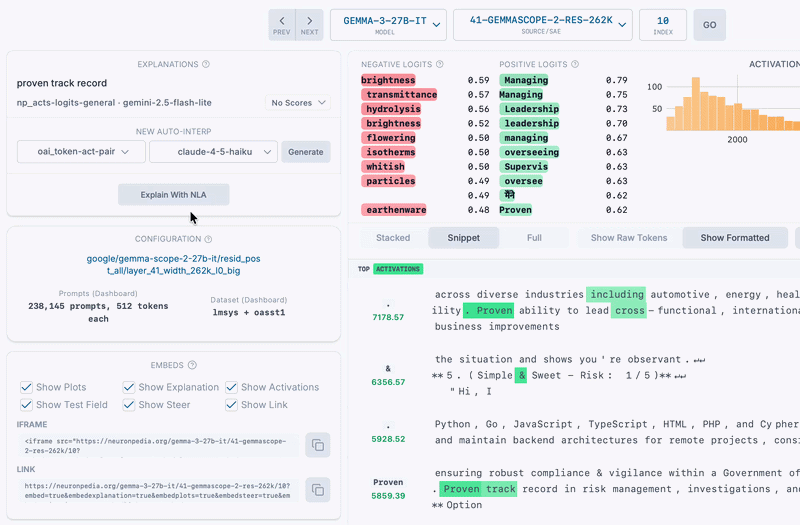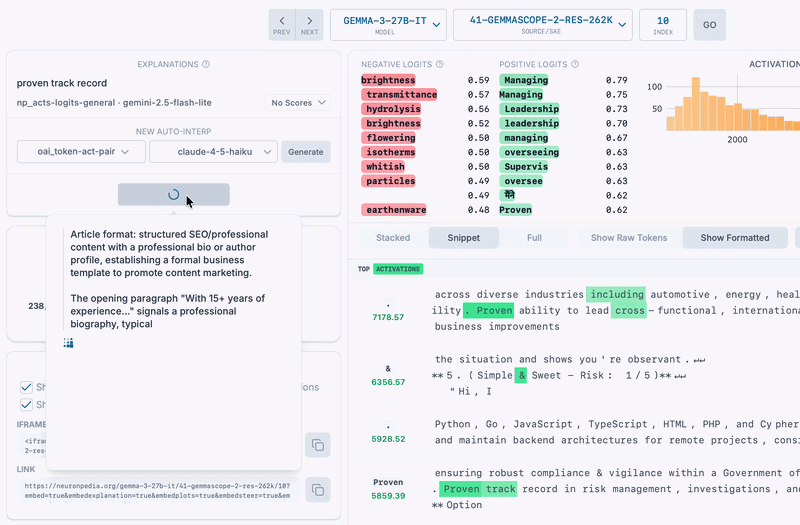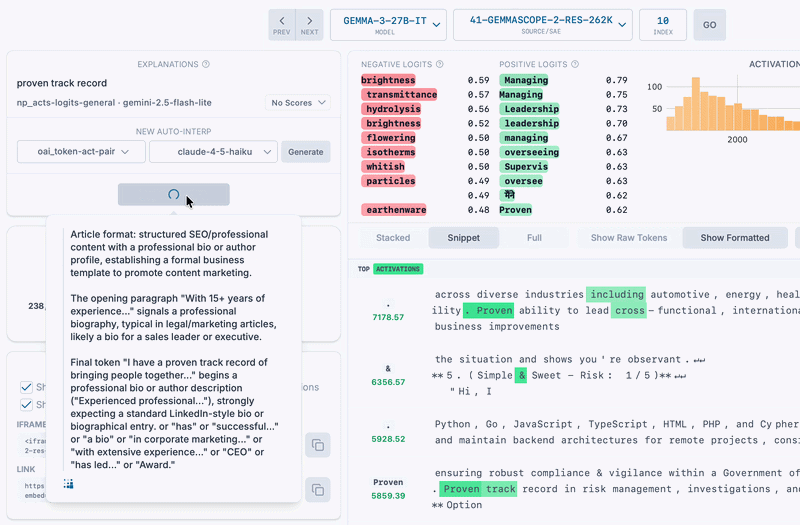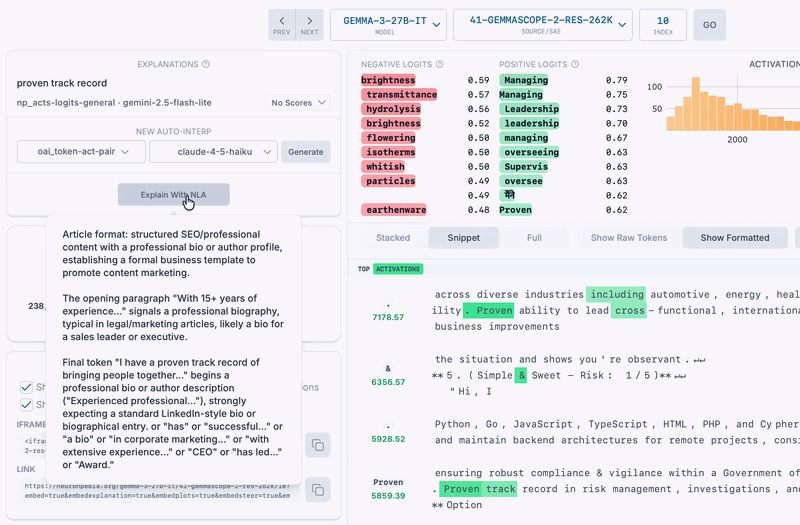
Here's Gemma's activation verbalizer labeling an SAE latent - its explanation is similar to the auto-interp label we generated with Gemini Flash 2.5.
We found that NLAs can do labeling of SAE latents, with no modification required. Instead of explaining a model's activations at a specific position in a conversation, here we simply pass the SAE vector to the NLA's activation verbalizer. This sometimes resulted in reasonable explanations matching the top activating texts for the latent (and also sometimes matching auto-interp explanations too).
🙋 Opportunity to Contribute: Formal Writeup - We need a writeup and theory of why this works, ideally with real tests and fleshed out experiments. Francesco Zaffino is working on formalizing a notebook that improves NLA labels and shows comparisons of Neuronpedia labels with NLA labels.
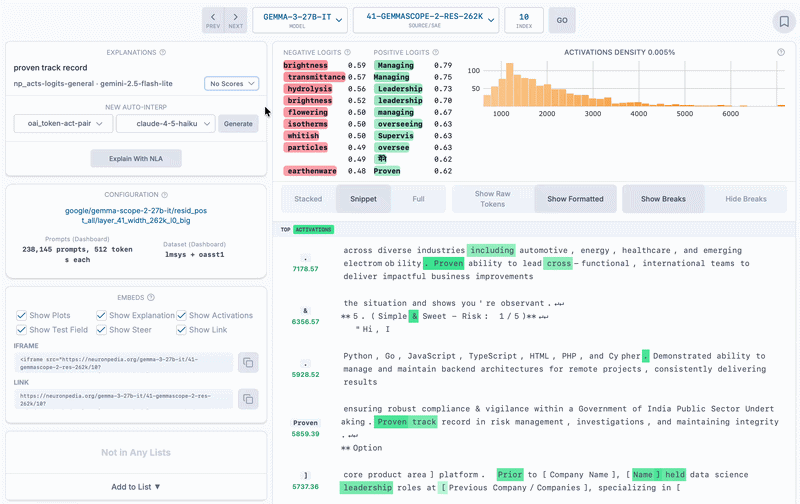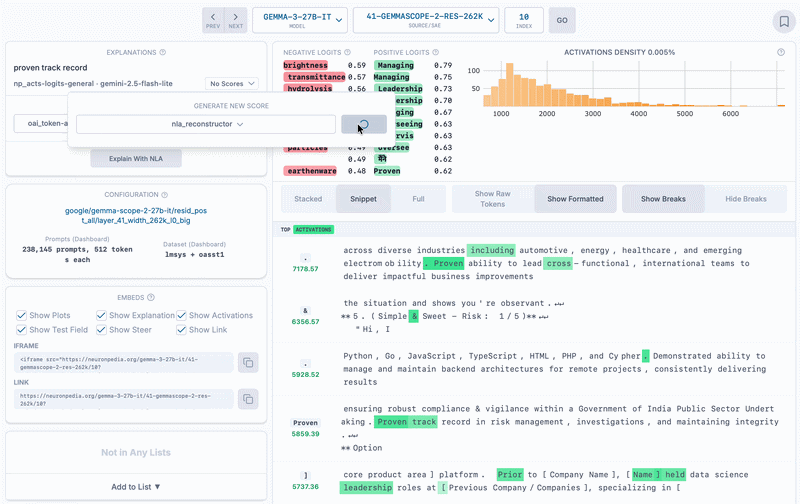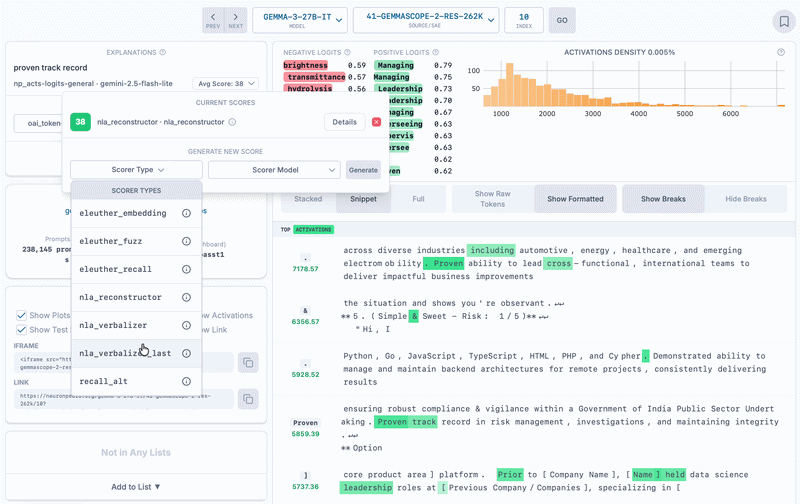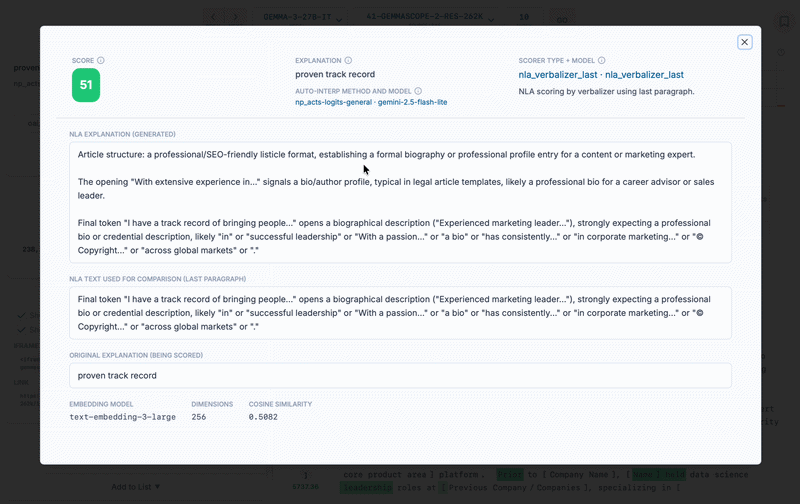
Demonstrating two methods of scoring non-NLA auto-interp explanations on the same SAE latent as above.
We found that NLAs can be used for scoring non-NLA auto-interp labels. We created three new explanation scoring methods on Neuronpedia using NLAs that can be used now:
nla_reconstructor: (Works Poorly) Pass the non-NLA feature label into the activation reconstructor to get an activation vector. Calculate cosine similarity between the resulting vector and the SAE vector. We found that with this method, the score was almost always very bad. This approach likely has some conceptual error - eg we probably need to do something to move the vector closer to the space of the model's activations.nla_verbalizer: (Works Okay) Generate an activation verbalizer explanation, then get its text embedding vector. Calculate cosine similarity between this vector and the text embedding vector of the feature label, which we use as the score.nla_verbalizer_last: (Works Okay+) Same as nla_verbalizer, except we only use the last paragraph of the activation verbalizer explanation when generating the text embedding vector. This works slightly better because the NLAs trained by kitft happened to generate three paragraph explanations, with the last paragraph about the token itself, and the first two paragraphs about greater context. But since NLA explanations will not always be structured this way, this explanation method is extremely hacky.We have more SAEs, dashboards, and auto-interps! These are middle layer SAEs different sizes. SAELens integration support by David Chanin.
As usual, the top activations, explanations, and other metadata are all available in our exports bucket:
Please do not hammer the API to get features individually. We do employ rate limiting so you will get errors back eventually, disrupting your workflow.
As always, please contact us with your questions, feedback, and suggestions.