
Hey all!
With frontier AI models, building interp applications/tools or getting started on research is cheap - it's often a matter of a few dollars and a well-crafted prompt. However, these outputs are not easily discoverable nor organized. So in addition to our usual collaborations and updates, we're releasing Interpretability Explorer (public beta) - a crowdsourced, categorized, and curated reference of tools, papers, replications, and other resources. It's still in early beta as our editors fill it out, but we're opening it up now for you to make contributions as well.
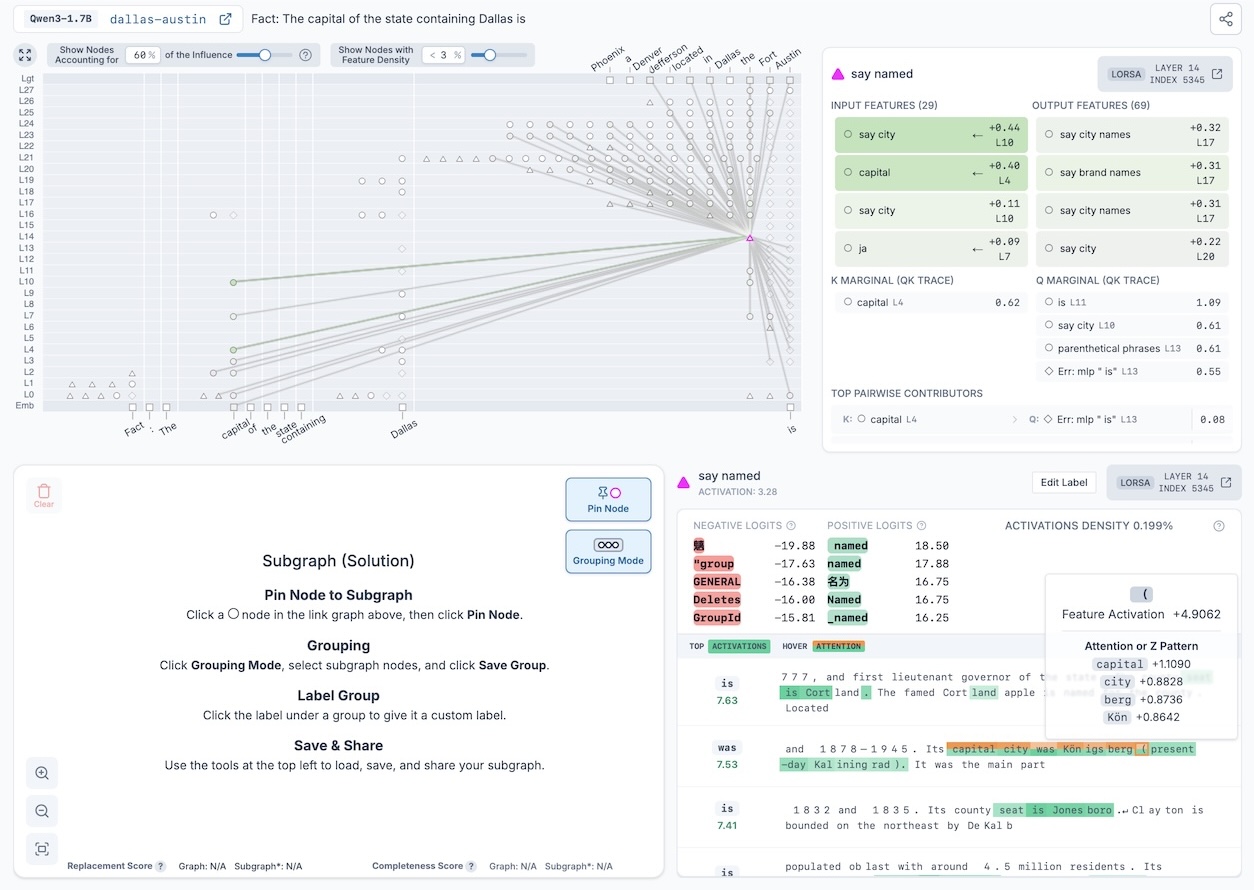
Recently, OpenMOSS extended Anthropic's circuit tracing work to add interpretable attention in addition to MLP transcoders, calling them Complete Replacement Models (CRMs). Neuronpedia now supports generating CRM graphs on Qwen3-1.7B.
CRM graphs have a new node type to represent attention called LORSA (Low-Rank Sparse Attention), which are displayed as triangle ▲ nodes to visually distinguish them from transcoder circle ⏺ nodes.
Since CRM graphs incorporate both transcoders and LORSA, they refer to two sets of dashboards. When selecting LORSA (triangle) nodes, you'll see the LORSA dashboard, which shows attention Z patterns when hovering over top activation tokens.
Additionally, LORSA nodes show QK tracing results under the Node Connections panel — including top marginal and pairwise (query-feature, key-feature) contributors. These tell us why a LORSA feature attends from one position to another.
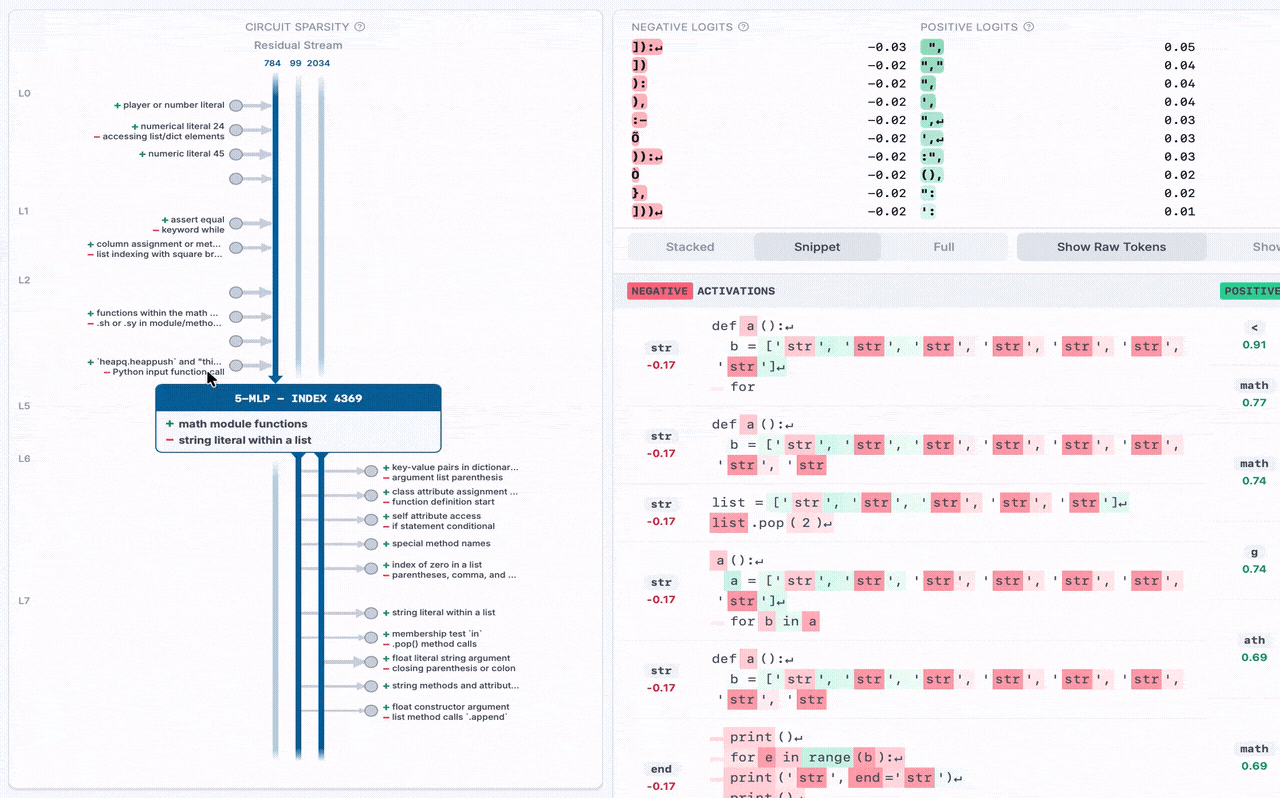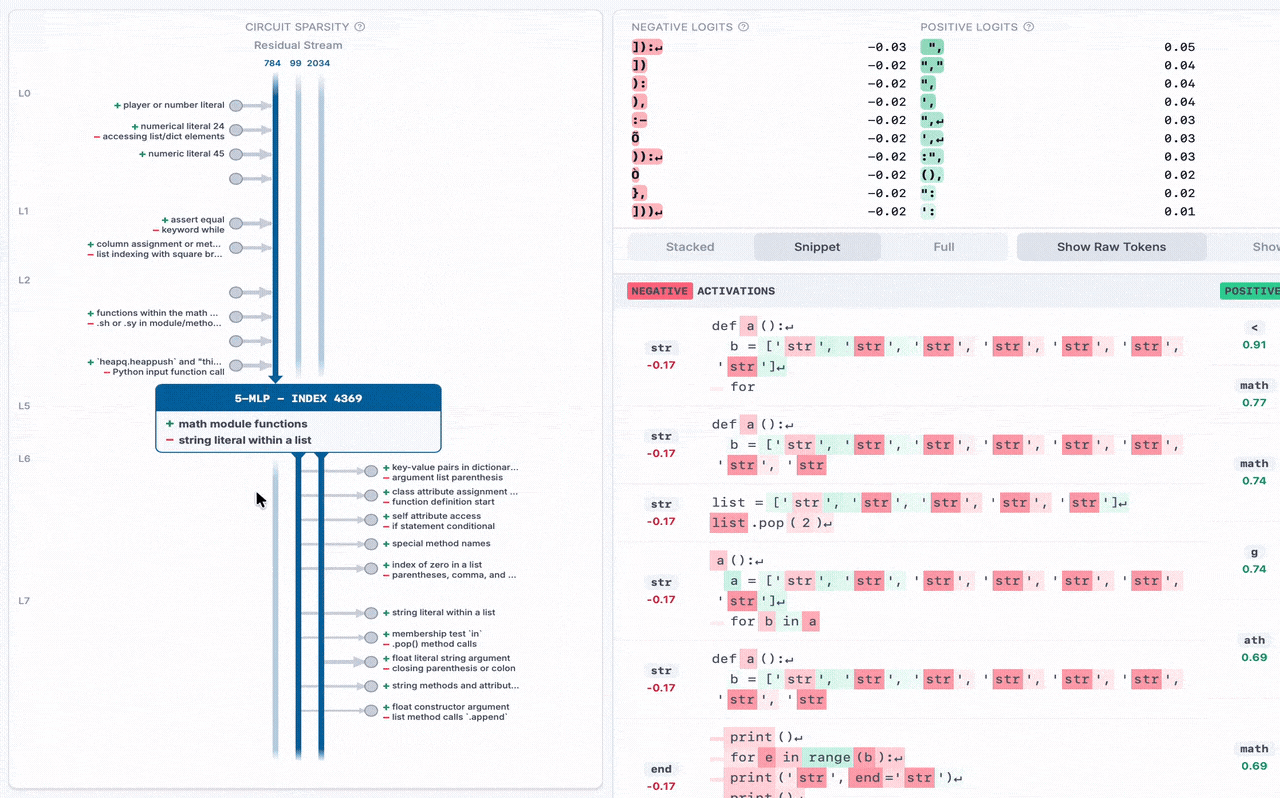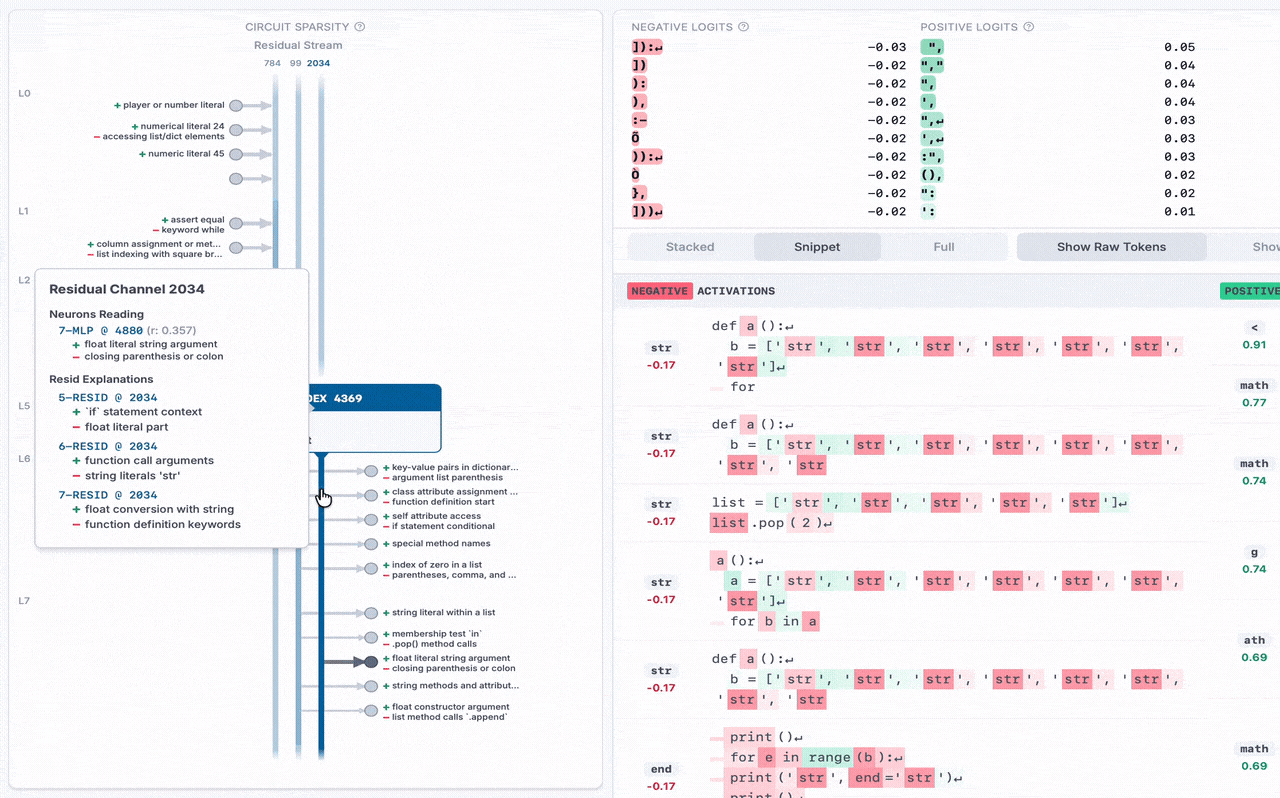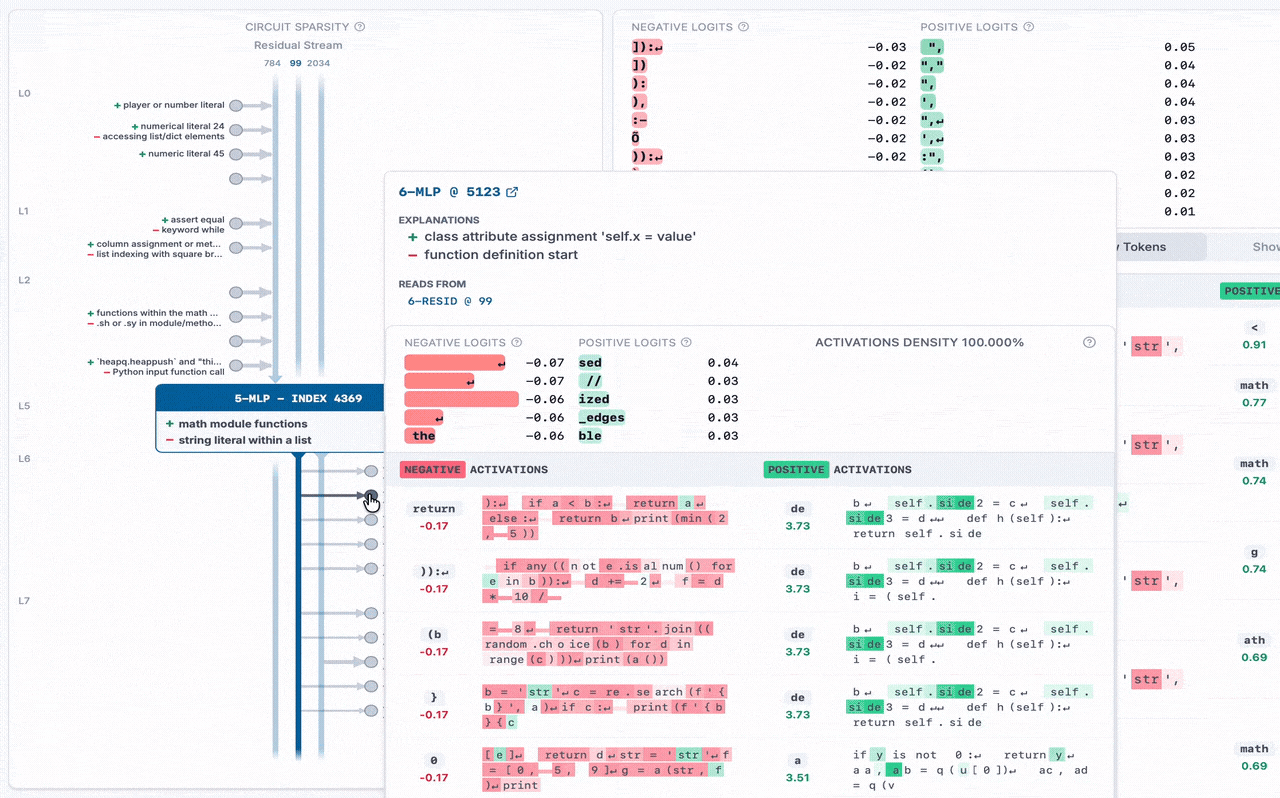
For the recent Weight-Sparse Transformers paper, we collaborated with OpenAI to release the following for the Python code model they trained:
Note: This work has not yet been fully validated - exercise caution before using it for research.
➡️ Visualizer + Release (MLP only): The residual channels are the vertical lines pointing down, which go into the current MLP neuron in the middle. Other residual stream channels exit the bottom of the MLP. On the sides, other MLP neurons write to and from residual channels, with their auto-interp labels displayed. You can hover over each MLP neuron and residual channel for details.
➡️ New Dashboard Variant: For this weight-sparse transformer, both positive and negative activations encode meaning, so we use a special dashboard that shows both the top positive and top negative activations side-by-side, and do auto-interp separately on each. In this example MLP, the top negative activations are the Python built-in function sorted, and the top positive activations are the keyword for.
➡️ New Python-Code Auto-Interp + Labels: Since this model is trained only on Python code, attempting to use existing auto-interp explainers yielded generic, unhelpful explanations like "snippets of code". So we wrote an explainer for Python code, which yields more specific labels like "for loop and its iterable". We use this auto-interp on all MLP neurons and residual channels at each layer.
➡️ "Simplified" Python Dataset: To generate the dashboards, we needed sample Python code. However, existing Python code datasets usually contain comments, variable names, and strings with words that this Python-code model wasn't trained on, resulting in uninterpretable top activations. So, we repurposed an existing Python dataset and simplified it to remove/replace unrecognized strings, and generated dashboards with this instead, resulting in more interpretable dashboards.
➡️ Weightpedia (Arnau MarinLlobet & Stefan Heimersheim): This wasn't created by us but it's awesome - it's a reference for interpreting individual weights of the same weight-sparse transformer. From Arnau:
Stefan Heimersheim and I are attempting to interpret individual weights of Gao et al.'s sparse transformer. We're examining random nonzero weights and trying to understand what each one does. Our current approach: for each weight, we ablate it (set to zero) and measure KL divergence across many dataset samples. We then inspect (1) dataset examples in different quantile bands of effect size, and (2) quantile-activating examples of the connected source and target activations. Our goal is to reach the bar of "can you write a regex or Python function that correctly predicts when this weight matters?" We've uploaded initial weight visualizations and specific case studies at: weightpedia.org.
Update July 2026 - We're pausing work on Interp Explorer as we figure out a more intuitive way to surface great interp content.
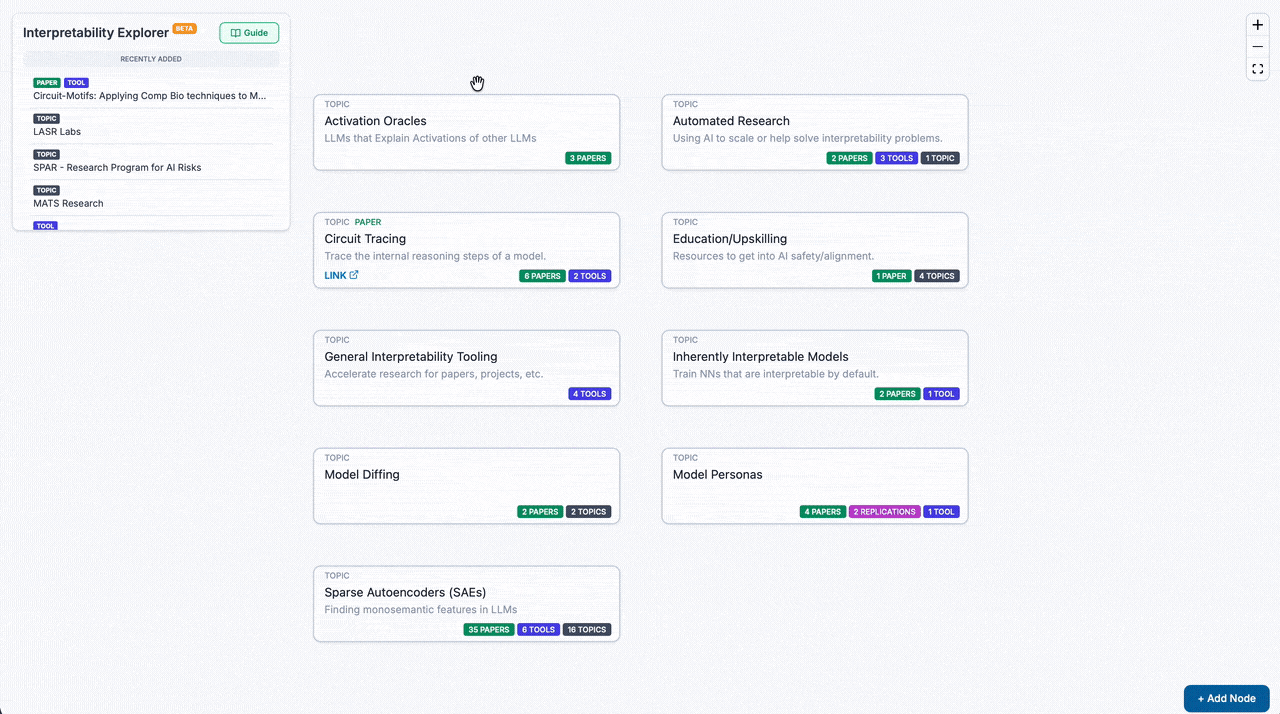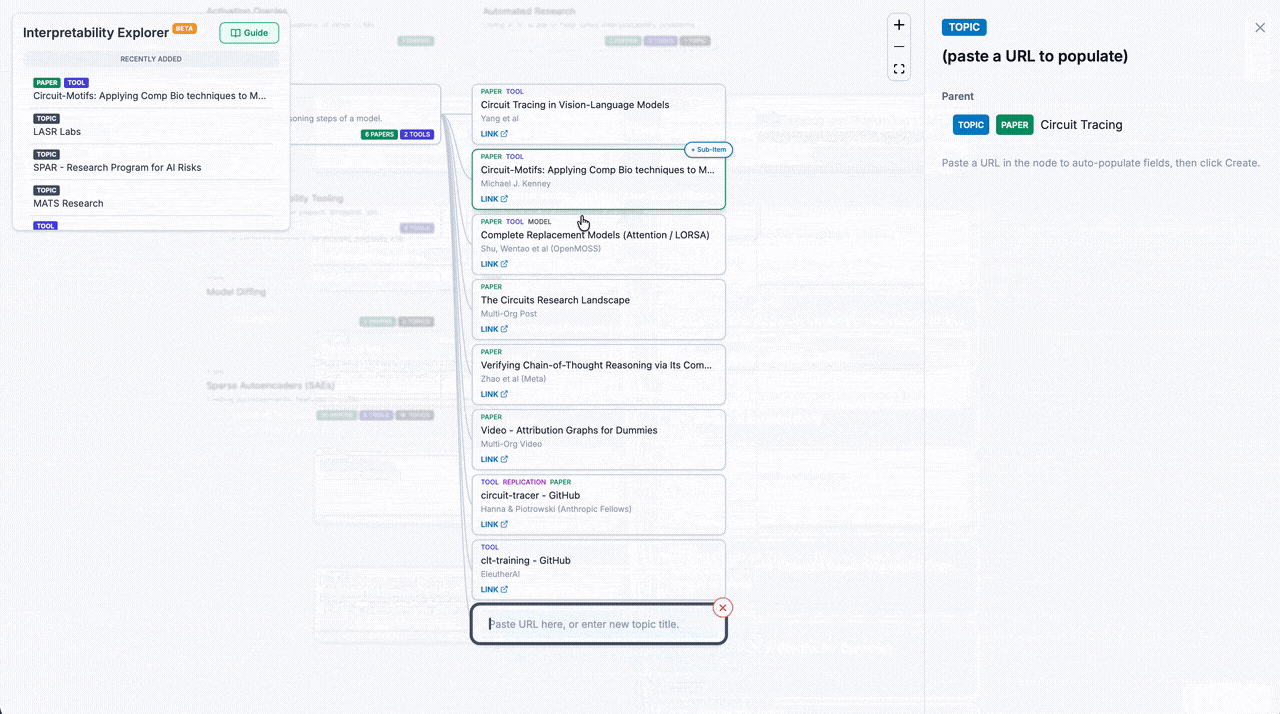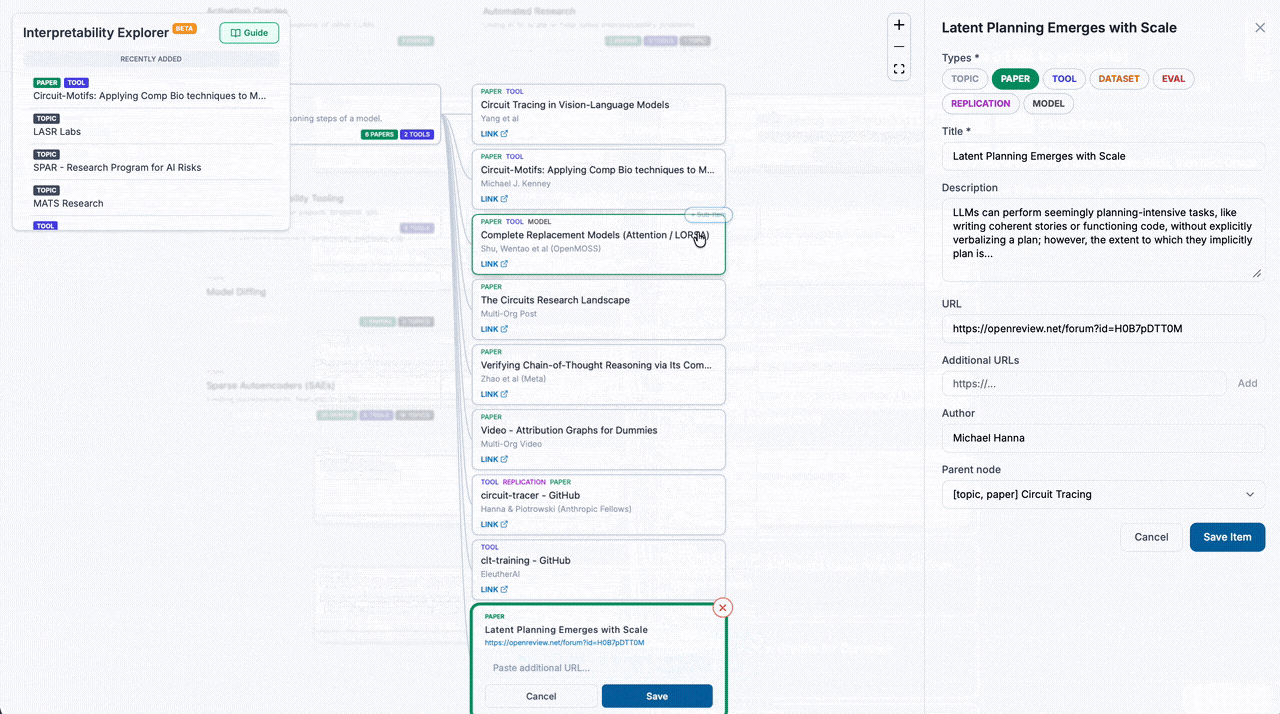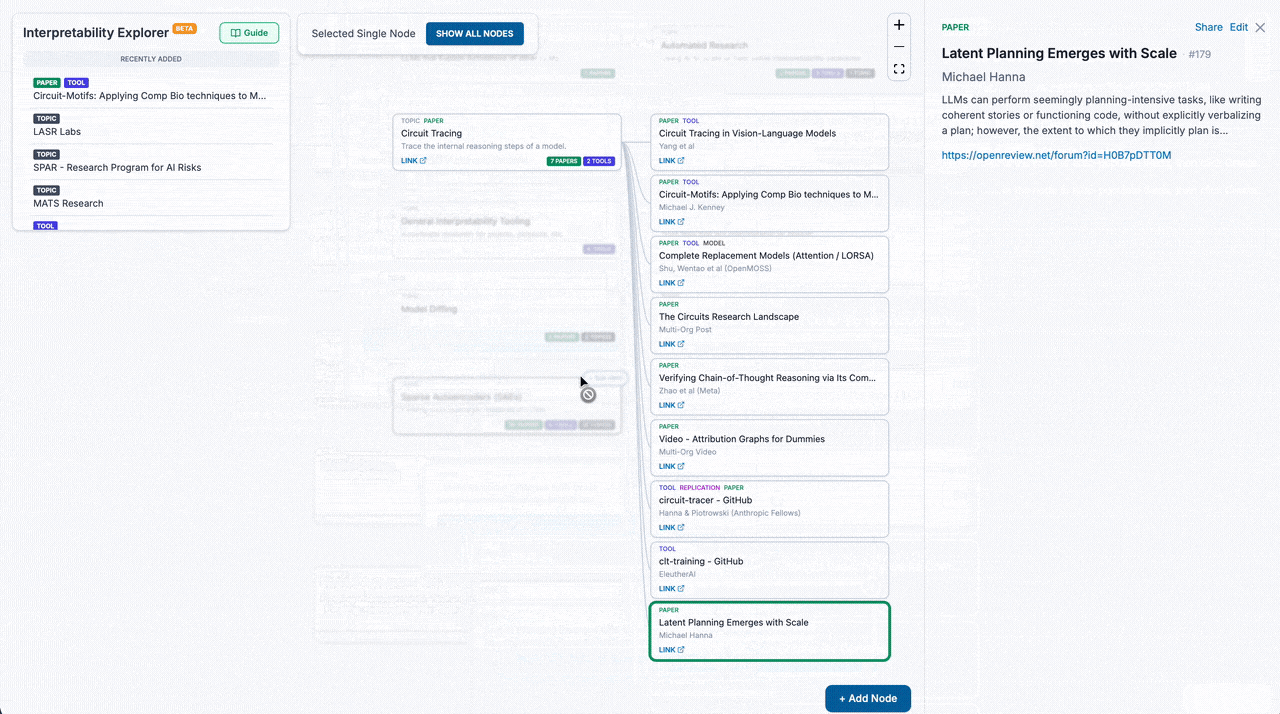
"What are the latest mech interp tools? What extension works have been done on circuit tracing? Are there any replications for this paper?" These are questions that we find ourselves and community members frequently asking. To help connect people to the most relevant resources in mech interp, Interpretability Explorer is a crowdsourced map of the latest tools, papers, replications, and more, grouped by topic.
Each node is directly linkable/sharable, so you can keep tabs on the topics that you care most about.
It's new and is still in the seeding phase - help fill it out! Hover over any topic/node and click "+ Sub-Item". A wide range of submissions are accepted: blog posts, agent skills, datasets, notebooks, Youtube videos, etc. Interp Explorer wants your favorite interp stuff, so that other people can find and use it too. And of course, feedback is welcome.
➡️ Launch Interpretability Explorer
SynthSAEBench is 16k synthetic features that allows easy benchmarking of SAE architectures against ground truth. It's the followup work that's a "reference implementation" using SAELens' Synthetic Data tools, with specific configurations to imitate real features. Benchmark results for five SAE architectures are below and linked here. As new SAE variants are added, we'll also run them on SynthSAEBench and include their results.
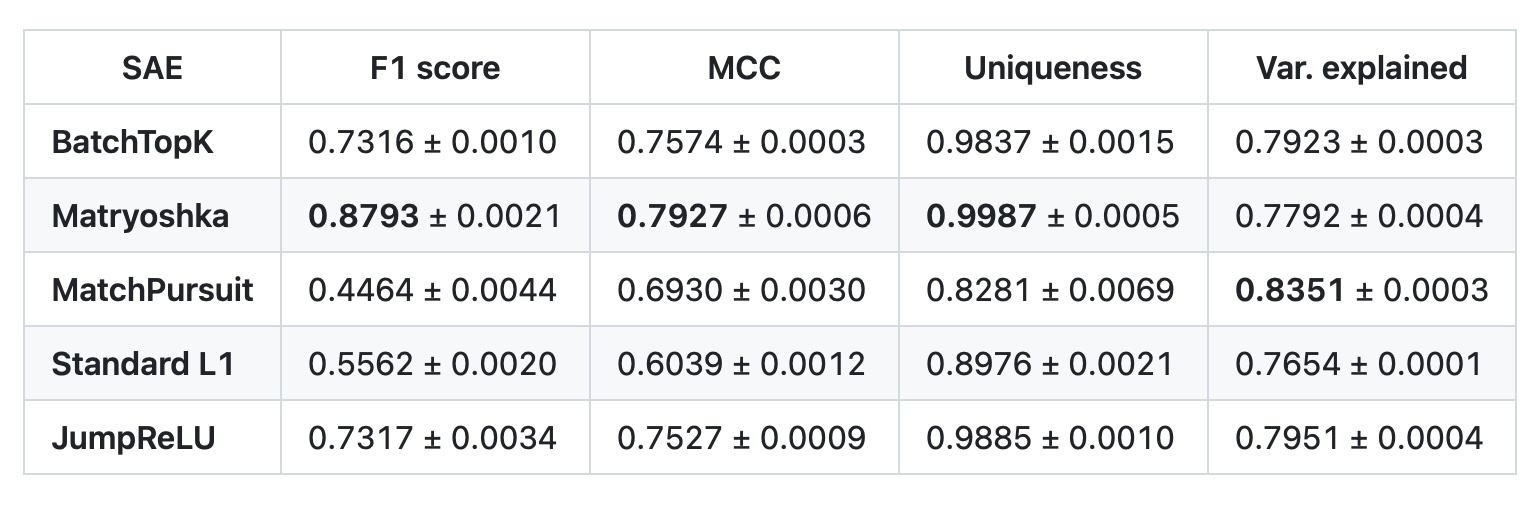
Inspired by Karpathy's autoresearch experiments, David also experimented with having Claude improve SAE performance autonomously against SynthSAEBench-16k, with interesting lessons learned.
To support compatibility for Zhao et al's (Meta) paper on circuit-tracer, Michael and Zheng Zhao added support for Top-K transcoders for PLTs. The Zhao et al transcoders can be loaded directly from here. Additionally, circuit-tracer now supports loading local features.
Michael on Slack:
Hi everyone! My name is Michael. My background and day job are in the physical sciences and ML. I'm very excited about the open interpretability community! I recently built a tool that applies network motif analysis (from systems biology) to attribution graphs. You can read about it in my blog post here and check out the tool here.
Michael's "circuit-motifs" tool loads any existing Neuronpedia-compatible graph and performs network motif analysis. Go check out his post and try it on your own graphs!
We're excited about the potential of cross-field pollination like this, especially from domain experts. Borrowing concepts from other fields lets us "stand on the shoulders of (similar) giants" and could help accelerate mech interp research in unexpected ways. These types of solutions also seem least likely for "autoresearch" agents to discover or try, thus giving humans an edge (for now 😅).
➡️ GitHub | 📃 Replication: Emotions | 🧑⚖️ Replication Review
MechInterp-Replication aims to be a easy-to-use harness for replicating mech interp papers across different models and vetting the replication's results - it even works locally on a Macbook.
Get Started With Claude Code/Codex (from the README):
Please replicate the Geometry of Truth paper using the zachgoldfine44/mechinterp-replication harness on the Qwen-2.5-1.5B-Instruct model locally, and then open a pull request to that repo with the results as a replication attempt when done.
Zach on Slack (shortened):
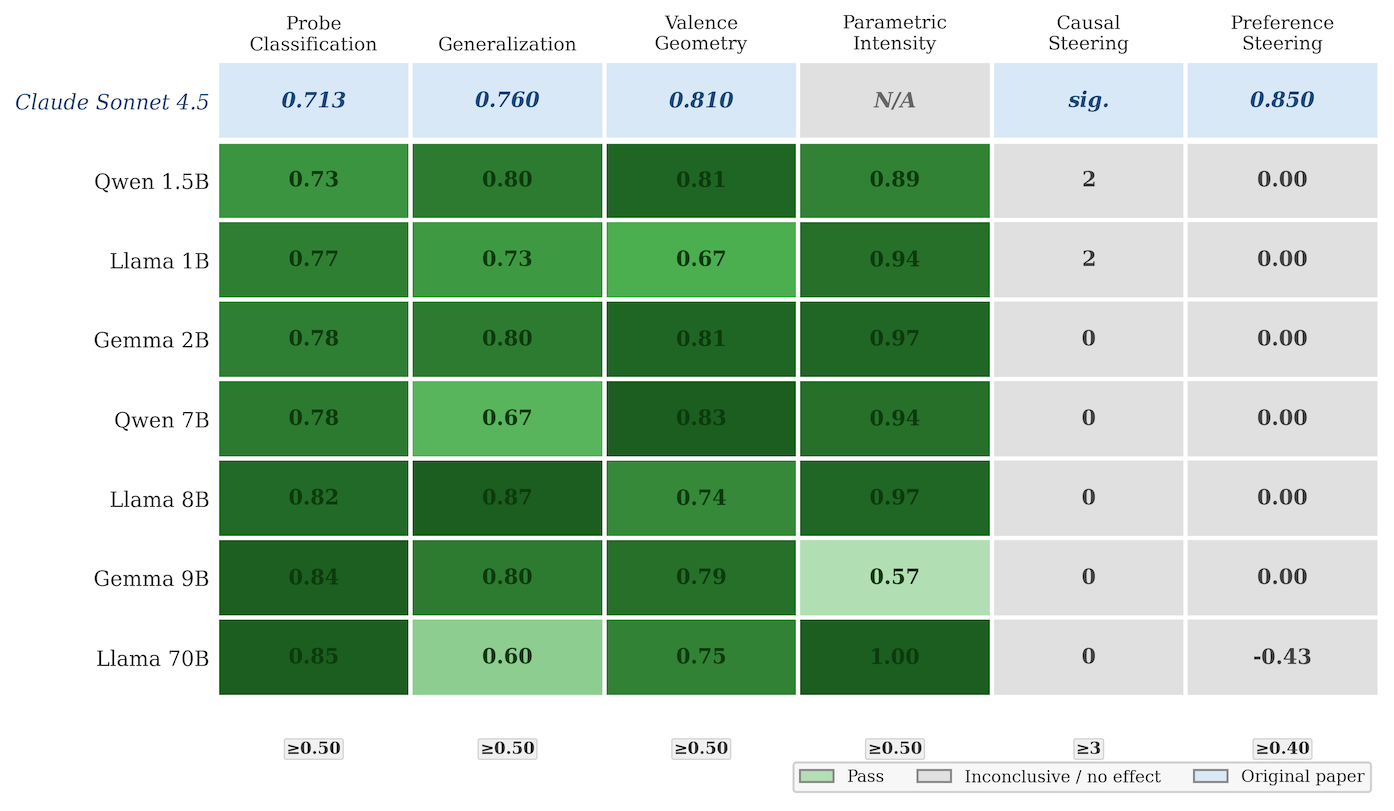
Hi! I'm currently learning mech interp research through the ARENA 3.0 curriculum. I built a harness to kickstart a shared resource to replicate more papers across models: MechInterp-Replication. In the repo I used the harness for an initial replication attempt: a draft replication of Anthropic's (Sofroniew et al.'s) recent Emotion Concepts paper across 6 open-source models (Llama / Qwen / Gemma, 1B–9B). Check it out and let me know what you think! And please use it to replicate a paper of your choosing, submit it, or suggest ways to improve the harness or existing replications.
We're particularly excited about a well-crafted harness that encourages standardized structures (eg tables like the one below), validation, and outputs relevant data and figures. We're looking forward to: generation of code/notebooks in addition to data/markdown (for quick re-replications), more models and larger sizes, and benchmarking against manual human/AI-assisted replications.
InterpKit wants to make it dead-simple to do interp on any HuggingFace model, minimizing the code and scaffolding necessary to get started on experiments. InterpKit runs locally and bundles each action into a one-line command or API call.
Example: With one CLI command, interpkit loads a model, extracts and applies a steering vector and compares the default and steered outputs:
interpkit steer gpt2 "My favorite animal is the" --positive " aquatic" --negative " earth" --at transformer.h.8 --scale 2

InterpKit is in early beta, but comes with example notebooks and is iterating quickly on features like cloud GPU offloading. We're excited to see become fully fleshed out and support even more advanced mech interp features.
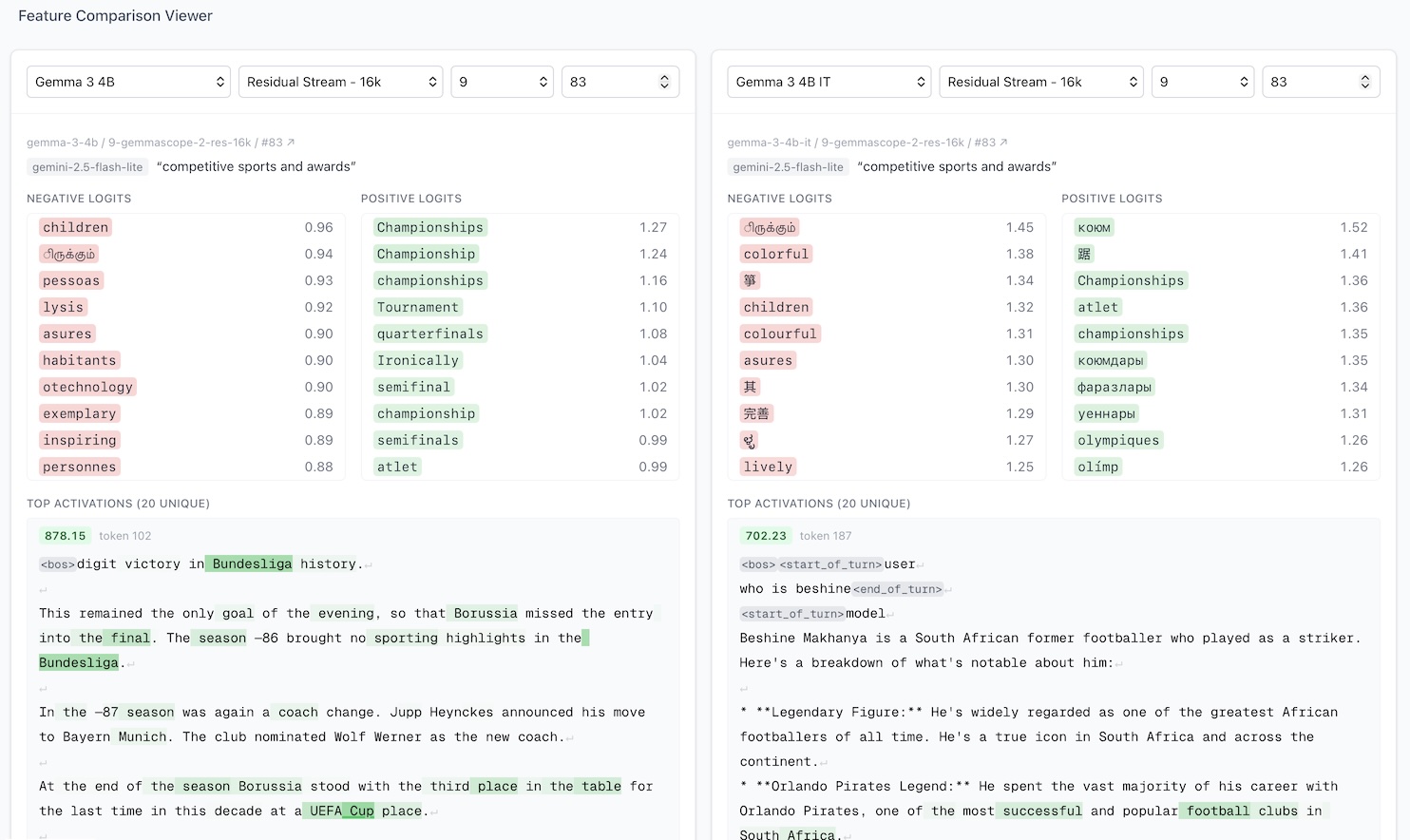
NP-Feature-Compare is hosted, open-source tool to quickly compare two features on Neuronpedia side-by-side. The interface is well designed with intuitive selectors, it's fast and loads features immediately, and it has directly sharable links. In the example, we compare a feature on Gemma 3 4B (pretrained/base) against the one on Gemma 3 4B Instruct.
As always, please contact us with your questions, feedback, and suggestions.